
中汽协会数据开源计划持续推进!Coral-data开源计划第2期之Sim-KITTI for 3D仿真数据集
我国智能驾驶行业数据领域正面临着数据体量不足、数据孤岛现象严重等诸多挑战,开放、统一的数据生态尚未形成。为助力行业解决这一痛点问题,中汽协会下属公司众链科技携手技术合作方IAE智行众维重磅发布Coral-Data(珊瑚数据)开源计划!该开源计划将陆续发布系列仿真测试场景集和训练数据集,着眼当下智能驾驶行业对算法训练及仿真测试应用的迫切数据需求,欢迎持续关注…
本期发布的Sim-KITTI for 3D数据集是在上期Sim-KITTI的基础上,增加仿真点云数据和3D目标物标注,以适应更广泛的算法训练需求。
在自动驾驶技术的研发过程中,高质量、海量的训练数据至关重要。随着技术的不断进步和量产的实现,智驾车辆对于提升感知识别和判断能力的需求日益增长。为了进一步提升系统性能,除了常规数据,对于极限和边缘场景数据需求也变得尤为关键。然而,这类场景数据在现实世界中的发生概率低、采集难度大,且生产成本高,这成为了行业亟待解决的问题。
为了解决这些问题,中汽协会-众链科技携手IAE智行众维推出了Coral-data(珊瑚数据)开源计划。该计划基于自研DEEP OCEAN仿真软件工具平台(深海.AI)和科学有效的X-in-Loop仿真测试验证体系,致力于持续量产、验证和发布仿真数据集。开源计划首批发布了Sim-KITTI系列仿真数据集并验证了其在感知识别算法训练中的作用和有效性。


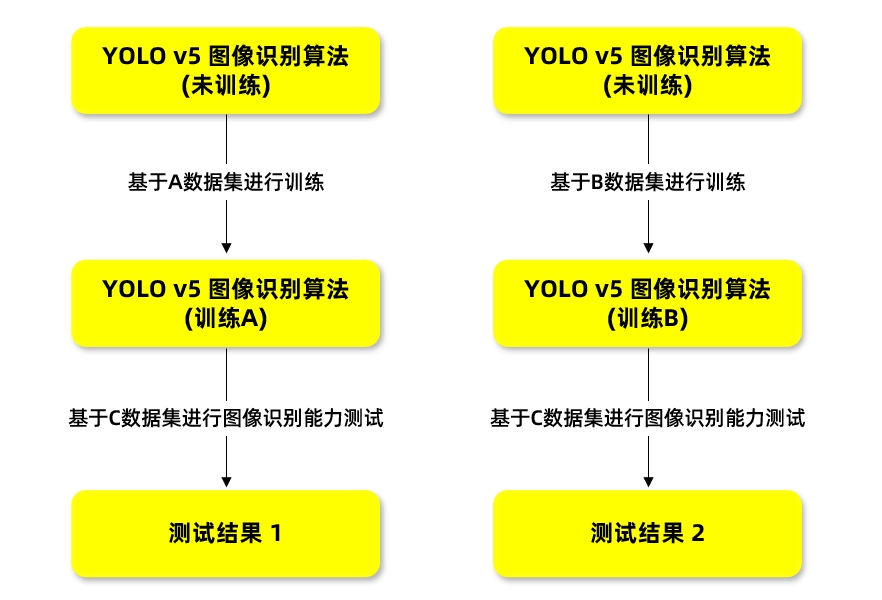
图像感知算法对同类型的目标标签数有一定要求,该组数据集中CAR类型目标占比较高,这里以针对CAR类型目标的测试结果进行对比说明。
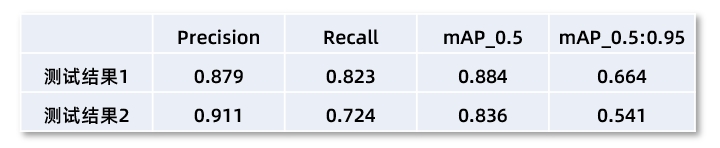
通过测试结果对比可以看到,采用DEEP OCEAN仿真平台生成的Sim-KITTI数据集对算法进行训练后,对真实图片中目标检测的结果与经过KITTI真实数据集训练后进行目标检测的结果精度相当,满足算法训练的基本要求。
研究表明,通过对仿真平台参数指标进行设计,对仿真数据集在图像风格、渲染等方面调整优化,可以有效提升仿真数据算法训练的质量。同时,通过X-in-Loop?仿真测试体系对Corner Case等场景进行闭环测试验证,可以有效保证仿真场景数据的质量。在自动驾驶技术的量产应用中,将一定比例的高质量仿真数据集融入到整体训练数据中,不仅能有效降低算法训练的成本,还能补充目前训练数据中缺少的Corner Case等关键数据,降本增效的同时提升算法可靠性。
基于DEEP OCEAN仿真平台和科学有效的测试验证体系,不仅可以生产高质量的摄像头图像训练数据,还可以同步获取毫米波雷达、激光雷达、姿态、定位等多种类型数据,为大模型、多模态算法训练提供重要支撑。在当前最热门的BEV算法开发训练中,许多企业面临训练数据标注难度大、效率低、缺乏Corner Case数据、数据覆盖性不足等问题,而基于DEEP OCEAN的仿真数据集则刚好可以帮助行业缓解甚至解决这些问题。随着Coral-data数据开源计划的推进,IAE智行众维?将陆续推出更多仿真训练和测试场景数据集,期待与业界同仁共同探索仿真技术和数据在智能驾驶领域的深度应用,共同推动自动驾驶技术的发展,为未来的智能交通体系贡献力量。
下载方式:
浏览器搜索下方链接可直接进入下载页
https://gitee.com/iae-icv/coral-data
KITTI数据集*
KITTI数据集是由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办的大型公开数据集,主要服务于自动驾驶和计算机视觉研究。该数据集包含丰富的传感器数据,如双目相机、64线激光雷达、GPS/IMU组合导航定位系统,以及大量的标定真值和开发工具。KITTI数据集的主要目的是评估计算机视觉技术在车载环境下的性能,涵盖立体图像、光流、视觉测距、3D物体检测和3D跟踪等多个方面。数据集覆盖了多种场景,如市区、乡村和高速公路,提供了真实场景下的多种情况,并且配有详细的标注信息。此外,KITTI数据集的传感器配置包括2个灰度摄像机、2个彩色摄像机、一个Velodyne 3D激光雷达、4个光学镜头以及1个GPS导航系统,这些配置保证了数据集提供高质量的图像和精确的定位数据。